
What Is a Neural Radiance Field?
A neural radiance field is a method for representing three-dimensional scenes as a continuous volumetric function learned by a neural network.
Given a set of two-dimensional photographs taken from different viewpoints, NeRF trains a deep learning model to predict the color and density of any point in 3D space, enabling the synthesis of photorealistic novel views of a scene that were never directly captured by a camera.
The technique was introduced by researchers at UC Berkeley, Google Research, and UC San Diego. It represented a fundamental shift in how computers reconstruct 3D environments. Traditional 3D reconstruction methods rely on explicit geometric representations such as meshes, point clouds, or voxel grids. NeRF replaces these with an implicit representation: a compact neural network that encodes an entire scene's appearance and geometry in its learned weights.
NeRF sits at the intersection of computer vision, generative modeling, and graphics rendering. It belongs to the broader class of neural scene representations that use artificial intelligence to learn how light interacts with objects and surfaces.
The result is a system that produces photorealistic images of a scene from arbitrary camera angles, complete with accurate lighting, reflections, and fine geometric detail.
How NeRF Works
Scene Representation as a Continuous Function
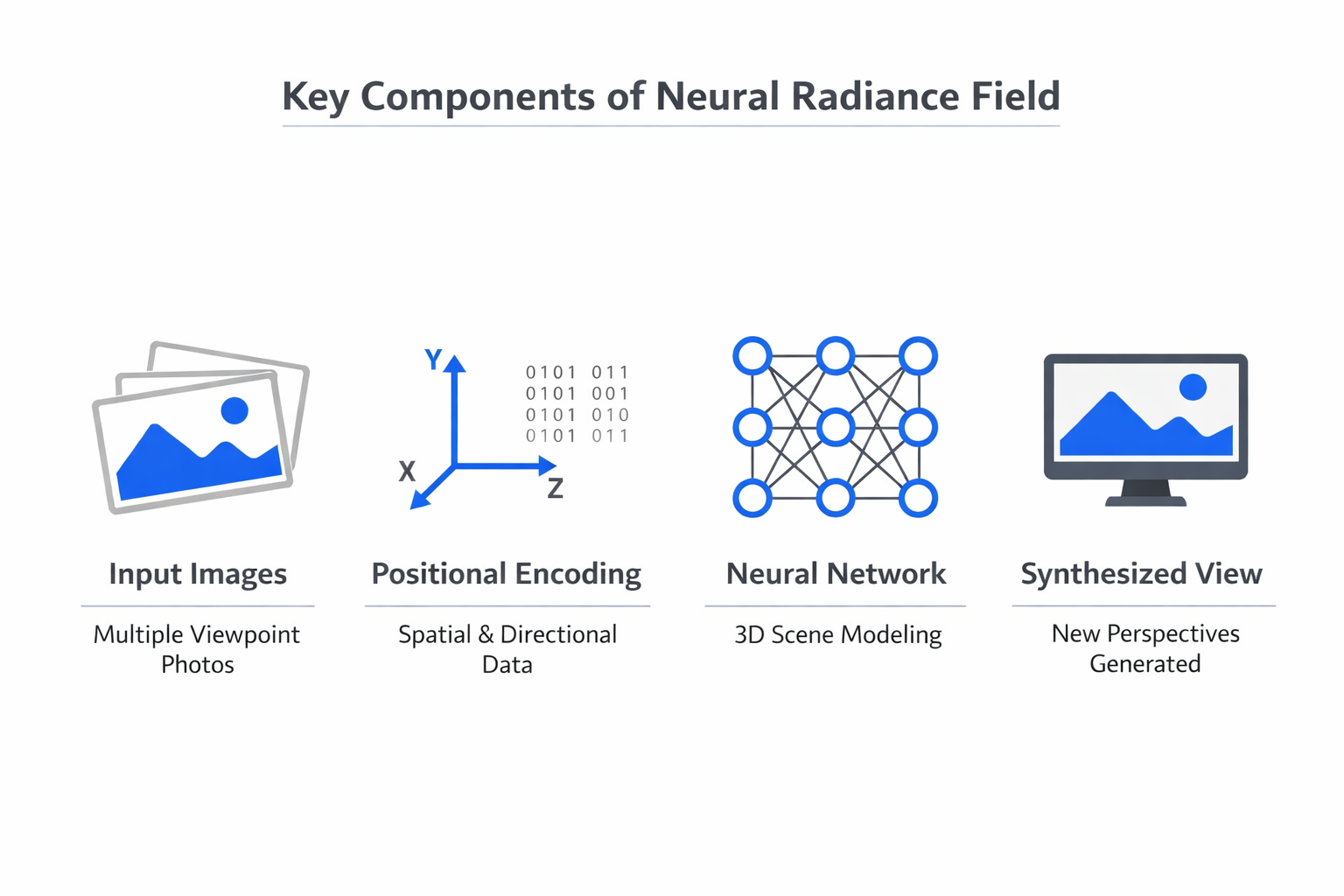
At its core, a neural radiance field models a scene as a continuous 5D function. The input consists of a 3D spatial coordinate (x, y, z) representing a point in space, plus a 2D viewing direction (theta, phi) describing the angle from which that point is observed. The output is a color value (RGB) and a volume density (sigma) at that point.
The density value indicates how much light is blocked at a given spatial location. High density means the point lies on or within a solid surface. Low density means the point is in empty space. The color depends on both spatial position and viewing direction, which allows the network to model view-dependent effects such as specular highlights and reflections that change as the observer moves.
This formulation requires no explicit 3D geometry. The network does not output triangles, vertices, or depth maps. It learns an implicit volumetric representation that can be queried at any resolution, keeping the scene representation continuous and theoretically infinite in detail.
The Neural Network Architecture
The underlying network is a multilayer perceptron (MLP), a relatively simple neural network consisting of fully connected layers. In the original NeRF implementation, the MLP has eight layers with 256 channels each. The spatial coordinates pass through the full network to produce density, while the viewing direction is concatenated at a later stage to produce view-dependent color.
Before entering the network, both the spatial coordinates and viewing directions are encoded using positional encoding, a technique that maps low-dimensional inputs into a higher-dimensional space using sinusoidal functions. This step is critical. Without positional encoding, the MLP struggles to represent high-frequency details such as sharp edges and fine textures. The encoding allows the network to learn rapid spatial variations that a plain coordinate input would smooth over.
This architectural choice contrasts with more complex architectures like convolutional neural networks or transformer models. The simplicity of the MLP is part of what makes NeRF computationally tractable for a single scene, though it also introduces limitations around scalability and generalization.
Volume Rendering
To generate an image from the learned radiance field, NeRF uses classical volume rendering principles adapted for differentiable computation. For each pixel in the target image, a ray is cast from the virtual camera through the scene. Points are sampled along each ray, and the network evaluates the color and density at each sample point.
The final pixel color is computed by accumulating the color contributions along the ray, weighted by how much light each point transmits. Points with high density contribute more to the final color; points in empty space contribute little. This accumulation process follows the standard volume rendering integral, discretized into a finite sum over the sampled points.
The entire rendering pipeline is differentiable, which means gradients can flow from the rendered pixel values back through the volume rendering equation and into the network weights. This is what enables end-to-end training. The network learns by comparing its rendered images against actual photographs and adjusting its weights to minimize the difference.
Hierarchical Sampling
Naively sampling points uniformly along each ray is inefficient because most of 3D space is empty. NeRF addresses this with a hierarchical sampling strategy that uses two networks: a coarse network and a fine network. The coarse network first evaluates a set of uniformly distributed samples along the ray. Its density predictions identify regions where surfaces are likely to exist.
The fine network then concentrates additional samples in those high-density regions, allocating computational resources where they matter most. This two-pass approach sharpens rendering quality without proportionally increasing computation. It lets NeRF capture thin structures and sharp boundaries that uniform sampling would miss.
Training Process
Training a neural radiance field requires a collection of input images with known camera positions and orientations. These camera parameters are typically obtained through a preprocessing step called structure-from-motion (SfM), which estimates camera poses from image correspondences. Tools like COLMAP are commonly used for this purpose.
During training, the network is optimized using machine learning techniques, specifically gradient descent with a photometric loss function. The loss measures the mean squared error between the rendered pixel colors and the ground truth pixel colors from the training images.
Over thousands of iterations, the network's weights converge to a representation that accurately reproduces the training views and generalizes to novel viewpoints.
Training a single NeRF model from scratch typically takes several hours on a modern GPU. Each scene requires its own trained network, which is both a strength (the model perfectly fits the specific scene) and a limitation (it cannot generalize across scenes without retraining).
| Component | Function | Key Detail |
|---|---|---|
| Scene Representation as a Continuous Function | At its core, a neural radiance field models a scene as a continuous 5D function. | Specular highlights and reflections that change as the observer moves |
| The Neural Network Architecture | The underlying network is a multilayer perceptron (MLP). | Sharp edges and fine textures |
| Volume Rendering | To generate an image from the learned radiance field. | For each pixel in the target image |
| Hierarchical Sampling | Naively sampling points uniformly along each ray is inefficient because most of 3D space. | — |
| Training Process | Training a neural radiance field requires a collection of input images with known camera. | This purpose |
Why NeRF Matters
Neural radiance fields matter because they demonstrated that a simple neural network could achieve photorealistic 3D reconstruction quality that previously required complex, hand-engineered graphics pipelines. The visual fidelity of NeRF outputs exceeded what prior neural rendering methods could produce, particularly for view-dependent effects like reflections, transparency, and fine geometric detail.
The significance extends beyond image quality. NeRF showed that implicit neural representations could serve as a viable alternative to explicit 3D formats. Traditional 3D representations like meshes and point clouds require manual creation or complex reconstruction algorithms and scale poorly with scene complexity. A neural radiance field compresses an entire scene into a set of network weights, typically a few megabytes, regardless of the scene's geometric complexity.
This compression property has practical implications. Storing and transmitting a NeRF model is far more efficient than transmitting dense point clouds or high-polygon meshes. For applications in virtual reality, augmented reality, and remote collaboration, this compact representation opens possibilities for streaming detailed 3D environments over bandwidth-limited connections.
NeRF also catalyzed a wave of follow-up research that has pushed the boundaries of neural rendering. Techniques like Instant NGP, Mip-NeRF, and 3D Gaussian Splatting built on NeRF's foundations to address its speed limitations, improve multi-scale rendering, and enable real-time applications.
The original paper has become one of the most cited works in the deep learning and computer vision communities, reflecting its broad impact on how researchers think about 3D scene understanding.
For practitioners working in generative AI, NeRF represents a bridge between 2D image generation and full 3D content creation. As diffusion models and other generative systems increasingly produce 3D outputs, understanding the radiance field paradigm provides essential context for where the field is heading.
NeRF Use Cases
Virtual and Augmented Reality
NeRF enables the creation of photorealistic 3D environments from ordinary photographs, which has direct applications in virtual and augmented reality. Instead of manually modeling every object and surface in a scene, developers can capture a series of photos and generate a high-fidelity 3D representation automatically. This reduces the production cost and time required to build immersive VR and AR experiences.
View synthesis quality is particularly important in these contexts because users expect consistent, artifact-free visuals as they move through a virtual space. NeRF's ability to render convincing novel views makes it well suited for applications where the camera viewpoint changes continuously in response to user movement.
Robotics and Autonomous Navigation
Robots and self-driving vehicles benefit from accurate 3D scene understanding. NeRF-based representations can provide dense, continuous maps of an environment from camera data alone, without requiring expensive LiDAR sensors. Research groups have explored using NeRF for simultaneous localization and mapping (SLAM), path planning, and obstacle avoidance.
The advantage over traditional mapping approaches is that NeRF captures not just geometry but also appearance. This enables tasks like visual localization, where a robot determines its position by matching its current camera view against a NeRF-rendered prediction. The photorealistic rendering quality improves matching accuracy compared to sparse feature-based localization.
Cultural Heritage and Preservation
Museums, archaeological sites, and historical buildings can be digitally preserved using NeRF. Researchers and conservators capture photographs of artifacts or architectural spaces, and NeRF reconstructs detailed 3D representations that can be explored interactively. This is valuable for documentation, remote access to collections, and preservation planning for sites at risk of damage or decay.
The image recognition capabilities underlying NeRF make it particularly effective for capturing fine surface details like inscriptions, carvings, and texture variations that traditional photogrammetry methods sometimes miss or smooth over.
Film and Visual Effects
The film industry uses NeRF to capture real-world environments and integrate them into digital production pipelines. A film crew can photograph a location and generate a NeRF representation that allows virtual cameras to move through the space freely during post-production. This reduces the need for physical reshoots and provides directors with more creative flexibility.
NeRF is also being explored for digital human capture, where an actor's performance is recorded from multiple cameras and reconstructed as a renderable 3D model. This connects to broader work in image-to-image translation and appearance transfer, where the goal is to transform visual content while preserving identity and realism.
E-commerce and Product Visualization
Online retailers use NeRF to create interactive 3D product views from a small set of photographs. Instead of investing in full 3D modeling for every product in a catalog, a company can photograph items from multiple angles and generate a NeRF model that customers can rotate and inspect from any viewpoint. This improves the shopping experience and can reduce return rates by giving customers a better understanding of what they are buying.
Medical Imaging and Scientific Visualization
NeRF-style volumetric representations have potential applications in medical imaging, where 3D reconstruction from 2D scans (such as CT slices or MRI images) is a core task. While medical imaging has established reconstruction techniques, neural implicit representations offer advantages in interpolation quality and the ability to render smooth, continuous volumes from sparse input data.
In scientific visualization more broadly, NeRF can reconstruct complex 3D structures from microscopy images, satellite imagery, or industrial inspection data, extending its relevance well beyond consumer applications.
Challenges and Limitations
Training Speed
The original NeRF implementation requires hours of training on a high-end GPU to reconstruct a single scene. Each scene demands its own dedicated training run, and there is no built-in mechanism for transferring learned representations between scenes. This per-scene training requirement makes NeRF impractical for applications that need to process large numbers of scenes quickly.
Subsequent work has addressed this limitation significantly. Instant NGP (Neural Graphics Primitives) reduced training time from hours to seconds by using hash-based encoding instead of positional encoding. 3D Gaussian Splatting replaced the volume rendering pipeline entirely with a rasterization-based approach that achieves real-time rendering. These advances do not eliminate the training step, but they make it fast enough for many practical workflows.
Rendering Speed
Even after training, rendering a high-resolution image from a NeRF requires evaluating the network at millions of sample points, one for each ray through the scene. The original method produces roughly one frame per minute, far too slow for interactive applications. Real-time NeRF rendering has been a major research focus, with solutions ranging from baked representations to hardware-accelerated inference.
For teams building applications that require machine vision at interactive frame rates, the rendering bottleneck is a critical factor in choosing whether NeRF or a faster alternative like Gaussian Splatting is appropriate.
Scene Dynamics
Standard NeRF assumes a static scene. Moving objects, changing lighting, and deformable surfaces violate this assumption and produce artifacts in the reconstruction. Extensions like D-NeRF and Nerfies introduce time as an additional input dimension to model dynamic scenes, but these variants add complexity and require denser input data, often video rather than sparse photographs.
Handling dynamic environments remains one of the harder open problems in neural rendering. Real-world scenes frequently include motion (people walking, vehicles moving, foliage swaying), and a practical NeRF deployment pipeline must either handle or exclude these dynamic elements.
Camera Pose Estimation
NeRF depends on accurate camera pose information for each input image. Errors in camera positions or orientations directly translate to artifacts in the reconstruction. The standard preprocessing pipeline using COLMAP works well for structured image collections but can fail on textureless surfaces, repetitive patterns, or very wide baselines between views.
Some recent methods, including BARF (Bundle-Adjusting NeRF) and Nope-NeRF, attempt to jointly optimize camera poses and the radiance field during training, reducing the dependency on external pose estimation. However, these joint optimization approaches add training complexity and do not yet match the reliability of a well-conditioned SfM pipeline.
Generalization
A trained NeRF model represents exactly one scene. It cannot generalize to unseen scenes without retraining. This is fundamentally different from generative models trained on large datasets, which learn distributional patterns that transfer across inputs.
Efforts to build generalizable NeRF variants (like pixelNeRF and MVSNeRF) use image recognition features from pretrained convolutional neural networks to condition the radiance field on input images, enabling few-shot reconstruction. These methods trade some reconstruction quality for the ability to handle novel scenes without per-scene optimization.
Handling Unbounded and Large-Scale Scenes
The original NeRF formulation works best for bounded, object-centric scenes. Outdoor environments, large buildings, and landscape-scale scenes pose challenges because the coordinate space is unbounded and the range of distances from the camera varies enormously.
Extensions like NeRF++ and Mip-NeRF 360 address this with spatial warping functions and anti-aliasing techniques, but reconstructing large-scale scenes at high fidelity remains more difficult than capturing a single object on a turntable.
How to Get Started with NeRF
Getting started with neural radiance fields requires a combination of theoretical understanding and hands-on experimentation.
1. Build foundational knowledge. NeRF draws on concepts from computer graphics (ray casting, volume rendering), deep learning (MLPs, gradient descent, positional encoding), and photogrammetry (camera models, structure-from-motion). Familiarity with coordinate systems, rotation matrices, and the pinhole camera model is particularly important. Without these basics, the rendering pipeline will be difficult to debug.
2. Read the original paper and key follow-ups. The 2020 NeRF paper by Mildenhall et al. is accessible and well-written. Follow it with Instant NGP (for speed improvements), Mip-NeRF (for anti-aliasing), and 3D Gaussian Splatting (for a related but architecturally distinct approach). Understanding the evolution from NeRF to its successors gives valuable perspective on design trade-offs.
3. Set up a development environment. NeRF implementations typically require Python, PyTorch or JAX, and a CUDA-capable GPU. The Nerfstudio framework provides a well-documented, modular codebase that supports multiple NeRF variants and simplifies experimentation. Install it, run the provided tutorials, and reconstruct one of the standard benchmark scenes to verify your setup.
4. Capture your own data. Photograph a real-world scene or object from 30 to 100 viewpoints, ensuring good coverage of all angles and consistent lighting. Run COLMAP to estimate camera poses from your images. Then train a NeRF model on your own data. This end-to-end workflow reveals practical challenges (motion blur, inconsistent exposure, insufficient coverage) that benchmark datasets do not surface.
5. Experiment with variants. Try different NeRF implementations to understand their trade-offs. Compare the quality and speed of vanilla NeRF, Instant NGP, and Gaussian Splatting on the same scene. Experiment with different numbers of input views, scene types (indoor vs. outdoor, bounded vs. unbounded), and training configurations.
6. Explore integration with other systems. NeRF outputs can be converted to point clouds or meshes for use in standard 3D software. Explore how to extract geometry from a trained NeRF using marching cubes, or how to combine NeRF-based rendering with vision-language models for tasks like 3D scene understanding and semantic segmentation.
This integration work is where NeRF connects to the broader artificial intelligence ecosystem.
Teams building educational content around 3D AI and machine learning will find NeRF an effective teaching subject because it combines visual results with accessible mathematics, making abstract neural network concepts tangible.
FAQ
What is the difference between NeRF and photogrammetry?
Photogrammetry reconstructs 3D geometry by matching features across multiple photographs and triangulating their positions in space. The output is typically a point cloud or textured mesh. NeRF, by contrast, learns a continuous volumetric function that encodes both geometry and appearance in a neural network's weights. Photogrammetry produces explicit 3D structures that can be directly edited in standard software.
NeRF produces an implicit representation that excels at rendering photorealistic novel views but requires additional processing to extract editable geometry.
How many images does NeRF need?
The number of input images depends on the scene complexity and the desired reconstruction quality. For a simple object, 20 to 50 images may suffice. For complex scenes with intricate geometry and view-dependent effects, 100 to 300 images produce significantly better results. The images should cover the scene from diverse viewpoints with sufficient overlap. Sparse inputs lead to artifacts and missing detail, particularly in regions not well observed by the training cameras.
Can NeRF work in real time?
The original NeRF cannot render in real time due to the cost of evaluating a neural network at millions of points per frame. Subsequent methods have reached real-time performance. Instant NGP accelerates both training and rendering through hash-based spatial encoding. 3D Gaussian Splatting represents scenes as collections of Gaussian primitives rendered via rasterization rather than ray marching, which also runs in real time.
For interactive applications, these newer methods are generally preferred over the original NeRF formulation.
Does NeRF work for dynamic scenes?
Standard NeRF assumes a completely static scene. Dynamic elements like moving people or objects produce ghosting and blurring artifacts. Research extensions such as D-NeRF, Nerfies, and HyperNeRF add a temporal dimension to the radiance field, enabling reconstruction of deformable and moving scenes from video input. These methods require denser temporal sampling and more computation, and they do not yet match the quality of static NeRF on stationary scenes.
What hardware is required to train a NeRF?
Training a NeRF model requires a CUDA-capable NVIDIA GPU with at least 8 GB of VRAM. Higher-end GPUs (RTX 3090, RTX 4090, A100) significantly reduce training time. The original NeRF takes roughly 12 to 24 hours on a single V100 GPU. Instant NGP can train a comparable scene in under a minute on modern hardware. CPU-only training is technically possible but impractically slow, making a discrete GPU effectively a requirement.
How does NeRF relate to 3D Gaussian Splatting?
3D Gaussian Splatting is a neural rendering method inspired by the same goal as NeRF: synthesizing novel views from photographs. However, instead of using a neural network to represent a continuous radiance field, Gaussian Splatting represents the scene as a collection of 3D Gaussian primitives, each with a position, covariance, color, and opacity. These primitives are rendered using differentiable rasterization rather than volume rendering.
Gaussian Splatting achieves faster training and real-time rendering, making it more practical for interactive applications, while NeRF often produces smoother reconstructions of fine geometric detail.





