
What Is Perplexity AI?
Perplexity AI is an AI-powered search engine that combines large language models with real-time web retrieval to deliver direct, source-cited answers to user queries. Rather than returning a list of blue links like traditional search engines, Perplexity synthesizes information from multiple web sources and presents a coherent, conversational response with inline citations that link back to the original material.
The platform was founded in 2022 by Aravind Srinivas, Denis Yarats, Johnny Ho, and Andy Konwinski. Several of the founders came from backgrounds at OpenAI, Google, and Meta, bringing deep expertise in artificial intelligence and large-scale systems.
The company has raised significant venture capital and grown quickly, positioning itself as a credible alternative to both conventional search engines and standalone chatbots like ChatGPT.
What distinguishes Perplexity AI from a standard chatbot is its commitment to grounding every response in verifiable sources. While tools like ChatGPT Enterprise generate responses from pre-trained knowledge, Perplexity actively searches the live web at query time and ties each claim to a specific URL. This approach reduces hallucination risk and gives users a way to verify the information they receive.
How Perplexity AI Works
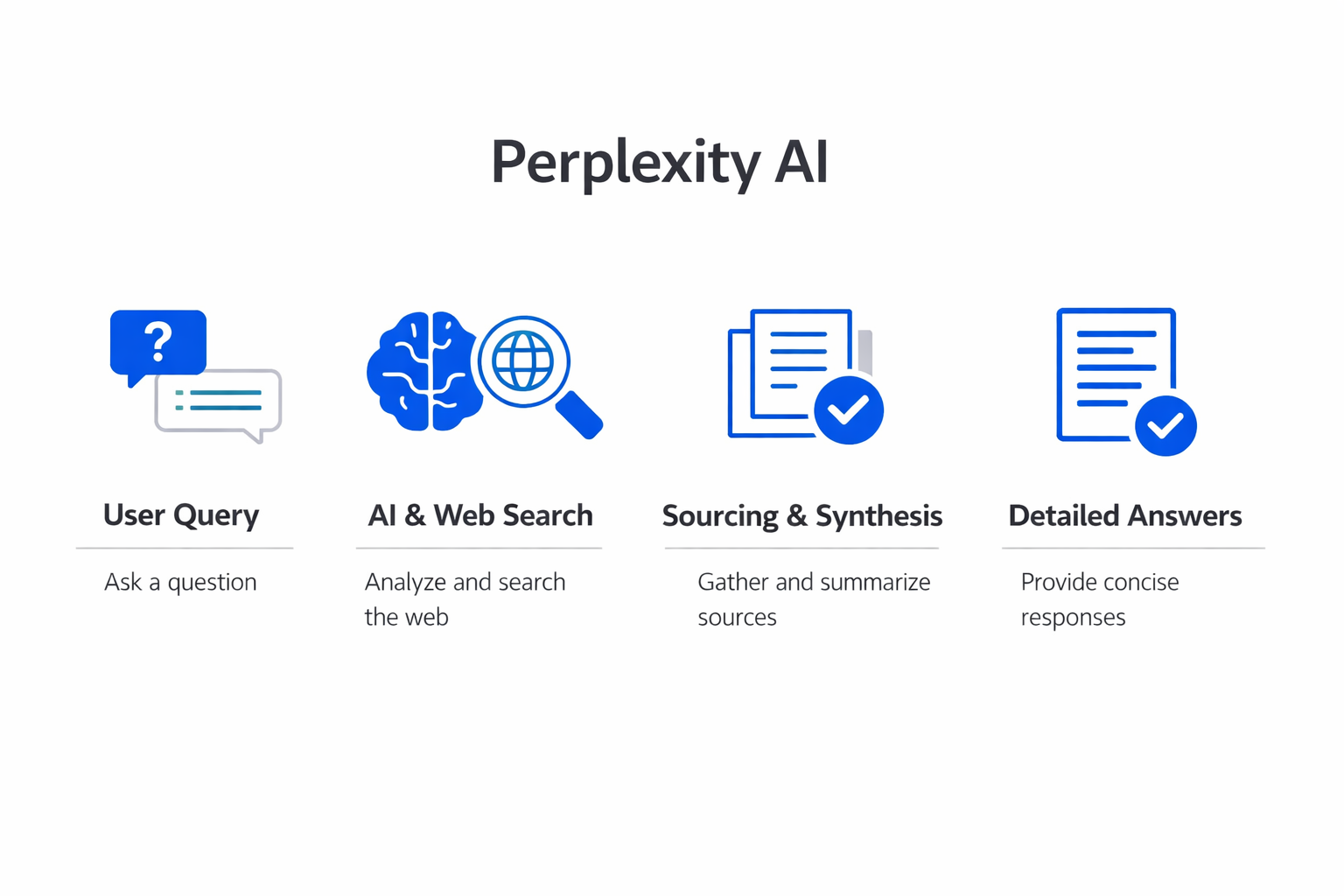
Perplexity AI operates on a retrieval-augmented generation (RAG) architecture. This means it does not rely solely on the static knowledge baked into a language model during training.
Instead, it combines two distinct processes: retrieving relevant information from the web in real time, and then using a generative AI model to synthesize that information into a readable answer.
When a user submits a query, Perplexity first interprets the intent using natural language processing techniques. The system then performs a web search across multiple sources, pulling in articles, research papers, forum posts, documentation, and other publicly available content. This retrieval step is what separates Perplexity from chatbots that answer purely from parametric memory.
The retrieved documents are then passed to a large language model, which reads, compresses, and synthesizes the relevant passages into a structured answer. The model is built on transformer model architecture, the same foundational technology behind models like GPT-3 and Google Gemini.
Each factual claim in the response is tagged with a numbered citation, allowing users to click through to the original source.
Perplexity also supports follow-up questions within the same conversation thread. The system maintains context across turns, so users can drill deeper into a topic without restating background information. This conversational layer uses semantic search principles to understand the relationship between the current question and previous exchanges, ensuring coherent multi-turn interactions.
The Pro tier goes further with access to more powerful models, including options from OpenAI, Anthropic, and Meta. Pro users can pick which model powers their search, balancing speed, depth, and reasoning depending on the task.
Key Features
Perplexity AI offers a set of features designed to make research faster, more transparent, and more interactive than traditional search. The following capabilities define the core product.
Cited, Source-Backed Answers
Every response includes numbered inline citations linked to the original web sources. Users can verify any claim by clicking the citation, which opens the source page directly. This transparency layer is the single most important differentiator. It addresses the trust gap that exists with many generative AI tools, where outputs look authoritative but lack traceability.
Focus Modes
Perplexity allows users to narrow their search scope using Focus modes. These include options such as All (general web), Academic (scholarly papers and journals), Writing (compositional assistance without web search), Wolfram Alpha (computational and mathematical queries), YouTube (video content), and Reddit (community discussions). Focus modes let users target the type of source material most relevant to their question.
Collections
Users can organize related searches into Collections, which function as folders for research threads. Each Collection stores a set of queries and their responses, making it easy to revisit prior research, share findings with collaborators, or build up knowledge on a topic over multiple sessions. This feature is particularly useful for professionals conducting ongoing research across days or weeks.
Multi-Model Selection (Pro)
Pro subscribers can choose from multiple underlying language models. This includes models from OpenAI, Anthropic (Claude), and open-source options. Different models have different strengths. Some excel at creative reasoning, others at factual precision, and others at code generation. Giving users model choice adds a layer of flexibility not found in most competing products.
File Upload and Analysis
Perplexity supports uploading documents, including PDFs, text files, and images. Users can ask questions about uploaded content, request summaries, or ask the system to cross-reference an uploaded document with live web data. This combines the benefits of document analysis with real-time information retrieval.
Perplexity Pages
Perplexity Pages allows users to generate structured, shareable articles from their research threads. The system takes a topic and produces a multi-section page with headers, body text, and citations. Users can edit the generated content, adjust the audience level (beginner, advanced, general), and publish or share the page via a link. This transforms Perplexity from a search tool into a lightweight content creation platform.
API Access
Perplexity provides an API that developers can integrate into their own applications. The API supports the same retrieval-augmented search pipeline available in the consumer product, making it possible to embed Perplexity's sourced answers into custom tools, internal knowledge bases, or customer-facing applications. Developers working with frameworks like LangChain can plug the Perplexity API into broader AI workflows.
Perplexity Enterprise Pro
For organizations, Perplexity offers Enterprise Pro, which adds internal data search capabilities, SSO integration, admin controls, and data privacy protections. Enterprise Pro allows companies to connect internal knowledge bases so employees can search both the public web and proprietary company data from a single interface.
Perplexity AI Use Cases
The value of Perplexity AI extends across professional, academic, and personal contexts. The following use cases illustrate where the platform delivers meaningful efficiency gains.
Academic and Scientific Research
Researchers use Perplexity's Academic Focus mode to search scholarly databases and retrieve findings from peer-reviewed papers. The citation system allows researchers to quickly identify primary sources, evaluate the credibility of claims, and build literature reviews without manually searching multiple academic databases. The ability to ask follow-up questions helps narrow down from broad topic overviews to specific findings.
Market Research and Competitive Analysis
Business professionals use Perplexity to gather market intelligence, track competitor activity, and synthesize industry trends. Because responses include source links, analysts can trace data points back to their origin, which is essential for reports that will be reviewed by stakeholders. The Collections feature allows teams to maintain running research threads on key competitors or market segments.
Technical Documentation and Development
Software engineers and technical writers use Perplexity to look up API documentation, debug error messages, compare framework options, and summarize technical concepts. The platform's ability to pull from Stack Overflow, GitHub, official documentation, and technical blogs makes it a practical alternative to manual documentation searches. Prompt engineering techniques can refine queries for more precise technical results.
Content Creation and Writing
Writers, marketers, and educators use Perplexity to research topics before writing. The Pages feature extends this further by generating draft articles that can serve as starting points for blog posts, reports, or educational materials. The cited sources provide a ready-made reference list that supports credible content creation.
Legal and Policy Research
Legal professionals use Perplexity to research case law, regulatory frameworks, and policy interpretations. The source-backed format is valuable in legal contexts where every claim must be traceable. While Perplexity should not replace specialized legal databases, it serves as a fast preliminary research tool that surfaces relevant starting points.
Education and Learning
Students and self-directed learners use Perplexity as a study companion. The conversational interface lets learners ask questions at their own level and drill progressively deeper into topics. The citation system teaches information literacy by showing where answers come from, reinforcing the habit of source verification.
Educators exploring machine learning concepts or other AI topics with students can use Perplexity to model effective research practices.
Daily Information Needs
Beyond professional use, Perplexity handles everyday questions with the same source-cited approach. Users ask about health topics, travel planning, product comparisons, cooking, news events, and general knowledge. The difference from a standard search engine is that Perplexity synthesizes the answer rather than requiring users to click through multiple results and piece information together manually.
Challenges and Limitations
Perplexity AI has grown quickly, but the platform has limitations that users should understand before relying on it as a primary research tool.
Source Quality Variability
Perplexity retrieves information from the open web, which means the quality of sources varies. A response might cite authoritative publications alongside low-quality blogs or outdated pages. Users must evaluate the credibility of cited sources themselves. The platform does not currently implement a strong source-ranking system that distinguishes between peer-reviewed research and opinion posts.
Publisher and Copyright Concerns
Perplexity's model of summarizing web content and presenting it directly to users has drawn criticism from publishers who argue that the platform reduces traffic to original content creators. Several major news organizations have raised concerns about how their content is used.
This tension between AI-driven summarization and content creator rights remains an open legal and ethical question across the artificial intelligence industry.
Hallucination Risk
While the retrieval-augmented approach reduces hallucinations compared to pure generative models, it does not eliminate them. The language model can still misinterpret retrieved content, draw incorrect inferences, or present information out of context. In high-stakes domains, users should treat Perplexity's outputs as starting points that require human verification, not as definitive answers.
Depth Limitations on Complex Topics
For highly specialized or technical queries, Perplexity's responses can lack the depth that a domain expert would expect. The system is optimized for breadth and accessibility, which means it may oversimplify nuanced topics. Professionals in fields like advanced machine learning research or specialized medicine may find that Perplexity's summaries miss critical subtleties.
Free Tier Restrictions
The free version of Perplexity limits the number of Pro searches (which use more powerful models) and restricts access to some features like file uploads and model selection. Users who need consistent access to the full feature set will need a Pro subscription. For teams, the Enterprise Pro tier adds further costs that must be justified against alternatives.
Real-Time Data Gaps
Perplexity searches the live web, but it does not index every source in real time. There can be delays between when information is published and when it becomes available in Perplexity's retrieval pipeline. For breaking news or rapidly evolving situations, traditional news sources or social media may still provide faster access to the latest information.
Source Quality Variability: Perplexity pulls from the open web, so cited sources range from authoritative to low quality. Mitigation: evaluate each source before trusting it.
Publisher and Copyright Concerns: Summarizing and presenting web content directly can reduce traffic to original creators. Mitigation: click through to and credit primary sources.
Hallucination Risk: Retrieval reduces but does not remove errors; the model can still misread sources. Mitigation: verify claims in high-stakes use.
Depth Limitations on Complex Topics: Optimized for breadth, it may oversimplify specialized subjects. Mitigation: consult domain experts for nuanced work.
Free Tier Restrictions: The free plan caps Pro searches and limits some features. Mitigation: upgrade to Pro for full access.
Real-Time Data Gaps: Not every source is indexed instantly. Mitigation: check news sources directly for breaking events.
How to Get Started with Perplexity AI
Getting started with Perplexity AI requires minimal setup. The platform is accessible through a web browser, mobile apps (iOS and Android), and a desktop application. The following steps outline the process.
Step 1: Create an Account. Visit perplexity.ai and sign up using an email address, Google account, or Apple ID. A free account provides access to the core search functionality with a limited number of Pro-level queries per day.
Step 2: Run Your First Query. Type a question into the search bar. Perplexity will return a synthesized answer with inline citations. Review the sources by clicking the numbered references to verify the information.
Step 3: Explore Focus Modes. Select a Focus mode before submitting your query to target specific source types. Use Academic for scholarly research, Reddit for community perspectives, or YouTube for video content. Experiment with different modes to see how they change the results.
Step 4: Organize Research with Collections. Create a Collection for any ongoing research topic. Add related queries to the same Collection to build a searchable archive of your findings. Share Collections with colleagues if you are working on collaborative projects.
Step 5: Try Pro Features. If the free tier meets your needs, continue using it. If you need more powerful models, unlimited Pro searches, or file uploads, consider upgrading to Pro. Perplexity offers monthly and annual billing.
Step 6: Integrate via API. For developers and teams building custom applications, explore the Perplexity API documentation. The API supports programmatic access to the same search and synthesis pipeline, enabling integration with internal tools, dashboards, or AI workflows built with orchestration libraries like LangChain.
Step 7: Evaluate Enterprise Pro. Organizations that need internal data search, SSO, admin controls, and data privacy protections should contact Perplexity's sales team to evaluate the Enterprise Pro offering. A structured pilot with a defined user group is the best way to assess fit before committing to a full deployment.
Understanding how to write effective prompts significantly improves the quality of Perplexity's responses. Users who invest time in learning basic prompt engineering techniques will get more precise, relevant, and useful answers from the platform.
The underlying technology relies on vector embeddings to match queries with relevant documents, so specificity and clarity in how questions are phrased directly impacts result quality.
FAQ
Is Perplexity AI free to use?
Perplexity AI offers a free tier with access to the core search functionality and a limited number of Pro-level queries per day (typically around five). The free version uses a standard model and provides cited answers for general queries. Upgrading to Perplexity Pro removes search limits, adds multiple model options, and includes features like file uploads and extended follow-up capabilities.
How is Perplexity AI different from ChatGPT?
The primary difference is that Perplexity AI searches the live web for every query and provides inline citations to its sources. ChatGPT primarily generates answers from its pre-trained knowledge without real-time retrieval (though it has added browsing capabilities in some tiers). Perplexity is designed as a research and information tool where source verification is central.
ChatGPT is a broader conversational assistant suited for generation, brainstorming, coding, and creative tasks where source attribution is less critical.
What models does Perplexity AI use?
Perplexity AI uses multiple large language models. The default free experience runs on a capable base model, while Pro subscribers can select from models including those from OpenAI, Anthropic, and open-source providers. The specific model roster evolves over time as new models are released. This multi-model approach, built on transformer model architecture, allows users to choose the best model for their specific task.
Can Perplexity AI be used for academic research?
Yes. Perplexity's Academic Focus mode specifically targets scholarly papers, journals, and research databases. The citation system provides direct links to source material, making it useful for building literature reviews and verifying claims against original research. However, it should complement, not replace, specialized academic databases like PubMed, IEEE Xplore, or Google Scholar for thorough research.
Does Perplexity AI store my search data?
Perplexity stores search history for logged-in users to enable features like Collections and search history. Users can delete individual searches or their entire history from the settings. The Enterprise Pro tier offers additional data privacy controls, including the ability to configure data retention policies. Users concerned about privacy should review Perplexity's current privacy policy for the most up-to-date information on data handling.
What is Perplexity Enterprise Pro?
Perplexity Enterprise Pro is the business tier designed for organizational deployment. It includes everything in the consumer Pro plan plus internal data search (allowing employees to query company knowledge bases alongside the public web), SSO integration, centralized admin controls, usage analytics, and data privacy protections. The product competes with enterprise search and knowledge management solutions by combining internal and external information retrieval in a single interface.





