
What Is Knowledge Engineering?
Knowledge engineering is the discipline within artificial intelligence that focuses on capturing, structuring, and encoding human expertise into formats that computer systems can use for reasoning and problem-solving. It is the bridge between what domain specialists know and what intelligent systems can do with that knowledge.
The goal is to extract knowledge from people who hold it, organize it into formal representations, and embed it in systems that can apply it consistently and at scale. That means identifying relevant concepts, defining the relationships between them, and encoding decision logic so software can replicate expert-level reasoning within a specific domain.
Knowledge engineering emerged in the 1970s and 1980s alongside the development of expert systems, which were among the first practical applications of AI. Researchers at Stanford, MIT, and Carnegie Mellon recognized that building intelligent systems required more than algorithms. It required a systematic approach to capturing the knowledge those algorithms would operate on.
The role of the knowledge engineer was formalized during this period as the person responsible for translating human expertise into machine-usable form.
The discipline has evolved significantly since then. Early knowledge engineering relied heavily on manual rule extraction through interviews with domain experts. Modern approaches incorporate machine learning, ontology design, and knowledge graphs to handle the scale and complexity of contemporary AI systems.
Despite these advances, the fundamental challenge remains the same: making implicit human knowledge explicit enough for machines to use.
How Knowledge Engineering Works
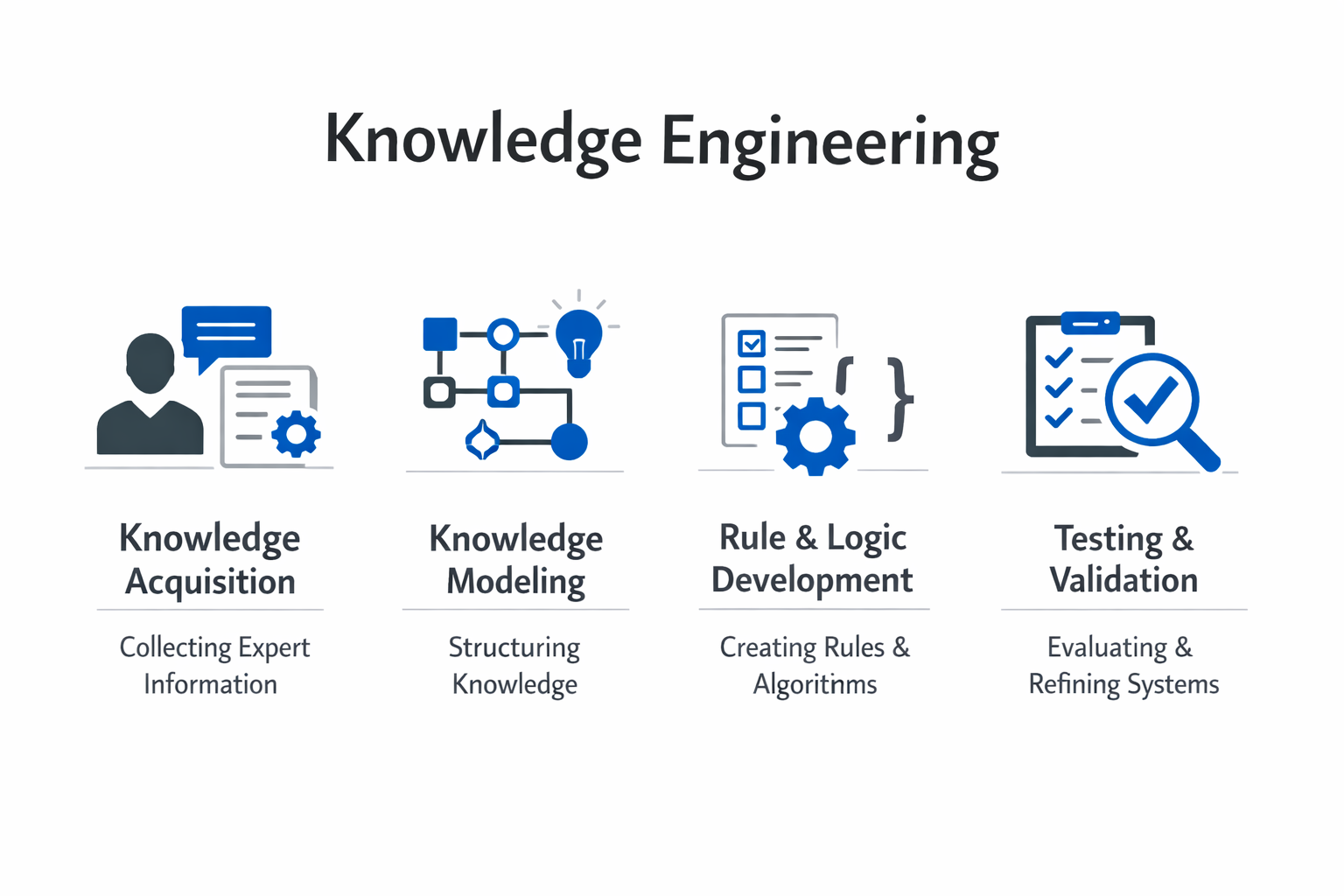
Knowledge engineering follows a structured process that turns raw expertise into working system components. Methodologies vary, but the workflow generally moves through five stages.
Knowledge Identification. The process begins by defining the scope of the problem domain and identifying what knowledge is needed. This involves working with stakeholders to determine which decisions the system must support, what expertise is required, and where that expertise currently resides. A knowledge engineer mapping a medical diagnosis domain, for example, would identify the symptoms, test results, diagnostic criteria, and treatment protocols that clinicians rely on.
Knowledge Acquisition. This is the most labor-intensive stage. Engineers extract expertise from specialists through structured interviews, observation, protocol analysis, and review of existing documentation. The difficulty is that much expert knowledge is tacit. Specialists often cannot articulate the reasoning behind their decisions because years of practice have made it automatic.
Skilled knowledge engineers use techniques like think-aloud protocols and scenario walkthroughs to surface this hidden expertise.
Knowledge Representation. Acquired knowledge must be encoded in a formal structure that a computer system can process. Common representation formats include production rules (IF-THEN statements), ontologies (formal descriptions of concepts and relationships), semantic networks, frames, and knowledge graphs. The choice of representation depends on the nature of the domain and the reasoning requirements of the target system.
Domains with clear decision trees favor rules. Domains with complex entity relationships favor ontologies or graph structures.
Knowledge Validation. Encoded knowledge must be tested against real-world scenarios to verify accuracy and completeness. This involves running the system through test cases, comparing its outputs against expert judgments, and identifying gaps or errors. Validation is iterative. Each round of testing reveals refinements needed in the knowledge base, which feeds back into acquisition and representation stages.
Knowledge Maintenance. Domain knowledge changes over time. Regulations shift, best practices evolve, and new information emerges. A knowledge engineering process must include provisions for ongoing updates to keep the system's knowledge base current and accurate. Without maintenance, even a well-built system degrades as its knowledge becomes outdated.
These stages do not always proceed linearly. In practice, knowledge engineering is iterative and often concurrent, with acquisition, representation, and validation overlapping as the system evolves.
Why Knowledge Engineering Matters
Knowledge engineering matters because intelligence, human or artificial, depends on the quality of the knowledge it operates on. An AI system with sophisticated algorithms but poorly structured knowledge will underperform a simpler system built on well-organized, accurate expertise.
For organizations, knowledge engineering addresses a critical operational risk: the loss of institutional expertise. When senior employees retire or leave, their accumulated knowledge often goes with them. Knowledge engineering provides a systematic method for capturing that expertise and preserving it in a form that survives personnel changes.
This is especially important in fields like healthcare, engineering, and law, where decisions carry significant consequences and expertise takes decades to develop.
Knowledge engineering also enables scalability. A human expert can advise one client at a time. A system built through knowledge engineering can serve thousands simultaneously with the same quality of reasoning. This scalability makes specialized expertise available in contexts where access to human specialists is limited by geography, cost, or availability.
The discipline is also central to building trustworthy AI. Systems grounded in explicitly engineered knowledge are inherently more transparent than black-box models. Every recommendation can be traced to a specific piece of encoded knowledge, supporting the kind of automated reasoning that regulated industries require.
This transparency is a significant advantage in environments where accountability and auditability are not optional.
In modern AI development, knowledge engineering supplies the structured foundation that data-driven approaches often lack. Natural language processing systems, retrieval-augmented generation architectures, and semantic search platforms all benefit from well-engineered knowledge structures that give meaning and context to raw data.
Knowledge Engineering Use Cases
Knowledge engineering applies wherever structured expertise must be embedded into computational systems. The following use cases represent established applications across industries.
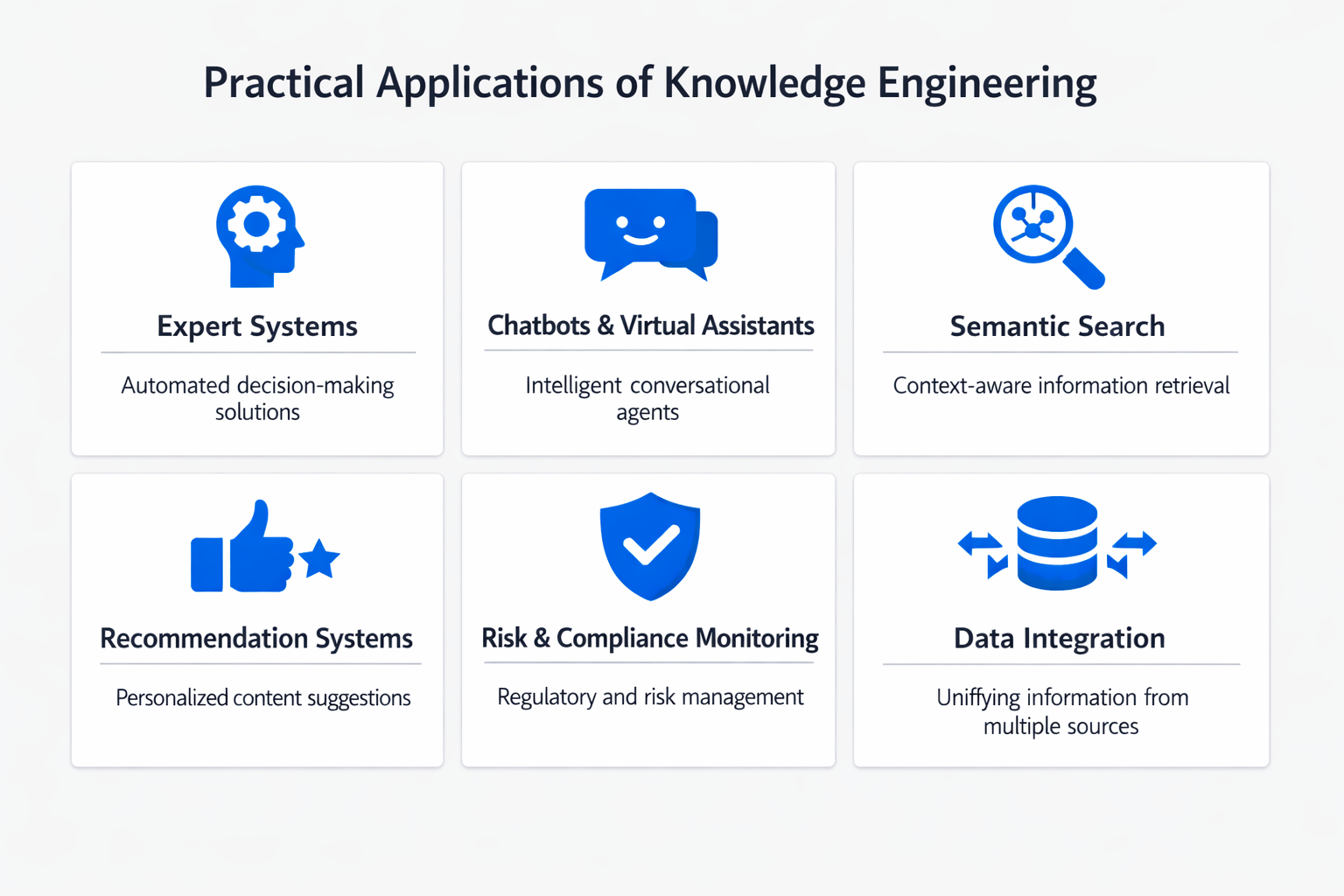
Expert Systems and Decision Support
The most direct application of knowledge engineering is building expert systems that replicate specialist reasoning. Medical diagnostic systems, financial risk assessment tools, and industrial troubleshooting platforms all rely on knowledge engineering to capture and formalize the decision logic of experienced professionals.
These systems use case-based reasoning or rule-based inference to match new problems against encoded expertise and generate recommendations.
Knowledge Graphs and Ontologies
Large-scale knowledge engineering efforts produce knowledge graphs and ontologies that organize vast amounts of domain knowledge into structured, queryable formats. Google's Knowledge Graph, biomedical ontologies like SNOMED CT, and enterprise knowledge management systems are all products of knowledge engineering.
These structures enable semantic search, contextual retrieval, and intelligent data integration across disparate sources.
Natural Language Understanding
Systems that interpret and respond to human language depend on encoded knowledge about language structure, meaning, and context. Knowledge engineering contributes the domain models, entity definitions, and relationship schemas that natural language understanding systems use to resolve ambiguity, extract intent, and generate accurate responses.
Without this structured knowledge, language models would lack the grounding needed to handle domain-specific queries reliably.
Intelligent Agents and Automation
Intelligent agents that operate autonomously in complex environments rely on engineered knowledge to guide their behavior. Whether the agent is managing a supply chain, monitoring network security, or tutoring a student, it needs a structured representation of its domain to make sound decisions. Knowledge engineering provides the conceptual models, decision rules, and constraint definitions that shape agent behavior.
Cognitive Computing and Hybrid AI
Cognitive computing platforms combine statistical learning with structured knowledge to handle tasks that require both pattern recognition and logical reasoning. Knowledge engineering supplies the structured component, providing ontologies, taxonomies, and inference rules that complement the pattern-matching capabilities of machine learning.
This hybrid approach is central to neuro-symbolic AI architectures that aim to combine the strengths of both paradigms.
Retrieval-Augmented Generation
Modern AI architectures increasingly use retrieval-augmented generation to ground large language models in factual knowledge. Knowledge engineering plays a critical role in curating, structuring, and maintaining the knowledge bases that these systems retrieve from.
The quality of the retrieval step depends directly on how well the underlying knowledge has been organized, a task that falls squarely within the knowledge engineering discipline.
| Use Case | Description | Impact |
|---|---|---|
| Expert systems | Encode specialist reasoning into rule-based decision support. | Consistent expert-level decisions at scale. |
| Knowledge graphs | Organize domain knowledge into structured, queryable formats. | Powering search, recommendations, and analytics. |
| Natural language understanding | Provide encoded knowledge about language structure and meaning. | Enabling chatbots, translation, and text analysis. |
| Intelligent agents | Guide autonomous agent behavior with engineered knowledge. | Reliable automation in complex environments. |
| Retrieval-augmented generation | Ground large language models in factual, structured knowledge. | Reducing hallucination and improving accuracy. |
Challenges and Limitations
Knowledge engineering faces several persistent challenges that affect both the feasibility and effectiveness of knowledge-based systems.
The Knowledge Acquisition Bottleneck. Extracting expertise from human specialists remains the most significant obstacle. Experts often possess tacit knowledge that they cannot easily articulate. They may disagree with one another. Their reasoning may be intuitive rather than rule-based. Knowledge engineers must invest substantial time in interviews, observation, and iterative refinement to surface and encode this knowledge accurately.
This bottleneck has been recognized since the earliest days of AI research and remains a defining constraint of the field.
Scalability. Manual knowledge engineering does not scale efficiently. Building a complete knowledge base for a complex domain can take years of effort from teams of knowledge engineers and domain experts. As domains grow in scope and complexity, the effort required to capture and maintain knowledge grows proportionally. Automated knowledge extraction from text and data offers some relief, but these methods introduce their own accuracy and quality challenges.
Knowledge Maintenance. Domains evolve. Medical guidelines change, regulations are updated, technology shifts, and best practices are revised. A knowledge base that is accurate today may be partially obsolete within months. Maintaining currency requires ongoing investment in monitoring, validation, and updating, costs that organizations sometimes underestimate when committing to knowledge-based approaches.
Handling Uncertainty and Ambiguity. Traditional knowledge engineering works best with crisp, deterministic knowledge. Real-world domains frequently involve uncertainty, incomplete information, and competing interpretations. While approaches like fuzzy logic and probabilistic reasoning can handle some degree of uncertainty, they add complexity to both the engineering process and the resulting system.
Integration with Data-Driven Approaches. Modern AI increasingly relies on statistical models trained on large datasets. Integrating explicitly engineered knowledge with data-driven models, as in neuro-symbolic AI, requires bridging two fundamentally different paradigms. Knowledge engineering produces symbolic, structured representations. Machine learning produces distributed, numerical representations. Aligning these two forms of knowledge within a single system remains an active area of research.
Domain Specificity. Knowledge engineering solutions are typically tied to specific domains. A knowledge base built for cardiology does not transfer to tax law. This domain specificity limits reuse and increases the total effort required when an organization needs knowledge-based systems across multiple areas.
How to Get Started
Building knowledge engineering capability requires a clear scope, the right team, and an iterative approach. The following steps provide a practical starting point for organizations or individuals entering this discipline.
Define the problem scope. Start with a specific, bounded problem rather than attempting to capture all knowledge in a domain. A focused scope, such as automating a particular diagnostic workflow or structuring expertise for a customer support system, makes the project manageable and delivers measurable results.
Assemble the team. Knowledge engineering requires two core roles: domain experts who hold the expertise and knowledge engineers who know how to extract and formalize it. In smaller teams, one person may fill both roles, but the distinction matters. The domain expert provides content. The knowledge engineer provides structure.
Choose a representation method. Select the knowledge representation that fits your domain and use case. For decision-heavy domains, production rules or decision tables work well. For domains with complex entity relationships, ontologies or knowledge graphs are more appropriate.
For domains that require reasoning from past examples, case-based reasoning may be the best fit.
Use established tools. Several mature tools support knowledge engineering workflows. Protege is a widely used open-source ontology editor. CLIPS and Drools provide rule-engine capabilities. Neo4j and similar graph databases support knowledge graph implementations.
For organizations working with transformer models and large language models, frameworks for retrieval-augmented generation provide infrastructure for connecting engineered knowledge to AI systems.
Iterate and validate. Build a small initial knowledge base, test it against real scenarios, gather feedback from domain experts, and refine. Do not try to build a complete system before testing. Iterative development catches errors early and produces better results than a single pass.
Plan for maintenance. Establish a process for reviewing and updating the knowledge base on a regular schedule. Assign ownership of the knowledge base to specific team members. Define triggers for review, such as regulatory changes, process updates, or performance degradation in the system.
FAQ
What is the difference between knowledge engineering and data engineering?
Data engineering focuses on building infrastructure for collecting, storing, and processing raw data. Knowledge engineering focuses on capturing, structuring, and encoding human expertise and domain understanding. Data engineering manages the pipeline. Knowledge engineering manages the meaning. Both are necessary for building intelligent systems, but they address different layers of the information stack.
Is knowledge engineering still relevant with modern machine learning?
Knowledge engineering is increasingly relevant, not less. Modern AI systems like retrieval-augmented generation architectures depend on well-structured knowledge bases to ground their outputs in factual, domain-specific information. Neuro-symbolic AI explicitly combines engineered knowledge with statistical learning.
As AI applications move into regulated and high-stakes domains, the need for structured, transparent, and auditable knowledge only grows.
What skills does a knowledge engineer need?
A knowledge engineer needs a combination of technical and interpersonal skills. On the technical side: proficiency in knowledge representation formalisms (ontologies, rules, graphs), familiarity with reasoning engines and knowledge management tools, and understanding of the AI systems the knowledge will serve.
On the interpersonal side: strong interviewing and elicitation skills, the ability to communicate across technical and non-technical boundaries, and patience for the iterative process of extracting and validating tacit expertise.
How does knowledge engineering relate to knowledge graphs?
A knowledge graph is one of the primary outputs of knowledge engineering. It is a structured representation of entities, relationships, and attributes within a domain, organized as a graph. Knowledge engineering provides the methodology for identifying what entities and relationships belong in the graph, how they should be defined, and how the graph should be validated and maintained. The knowledge graph is the product. Knowledge engineering is the process that creates it.
Can knowledge engineering be automated?
Partially. Automated knowledge extraction from text, databases, and other sources can accelerate the acquisition phase, particularly for factual knowledge that is already documented. Natural language processing techniques can identify entities, relationships, and patterns in unstructured text.
However, capturing nuanced expert judgment, resolving ambiguities, and validating the resulting knowledge base still require human involvement. Full automation of knowledge engineering remains an open research problem.





